
[Oracle] Wait event - Free Buffer Waits , db file parallel write, write complete waits
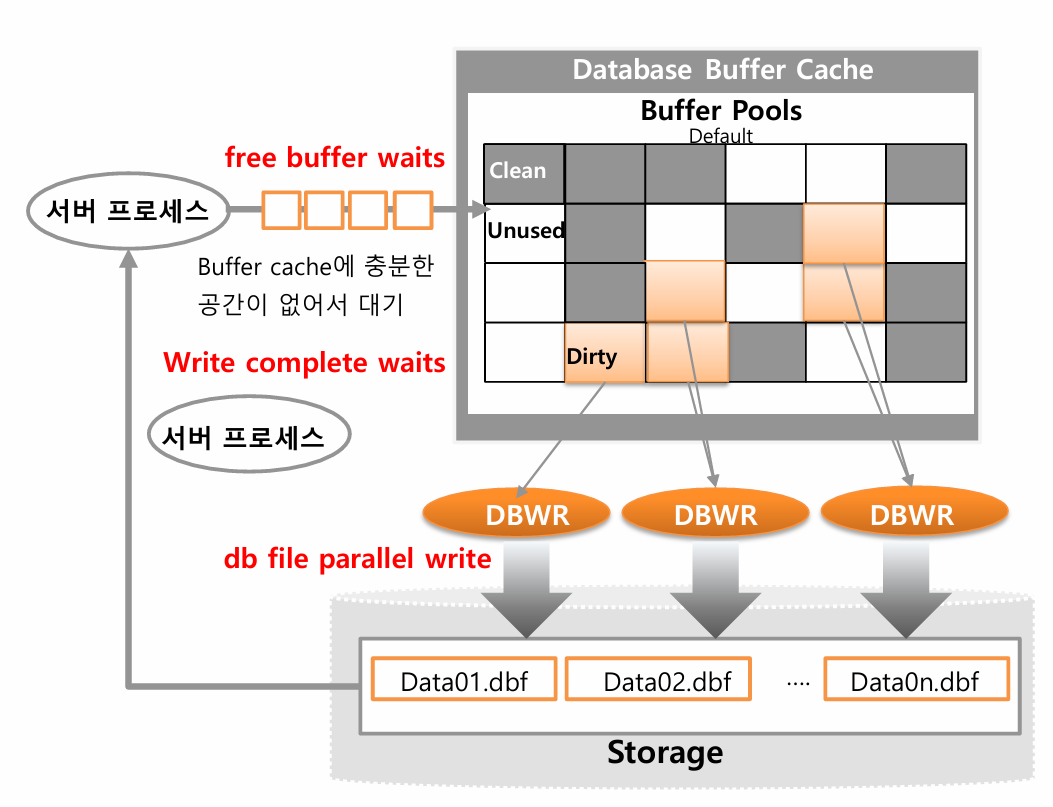
Free Buffer Waits
- buffer cache의 free buffer가 나올때까지 wait하는 거다
- server process가 storage 상에 데이터를 buffer에 올려야 하는데 free buffer가 없을 경우에 발생한다
- dirty buffer를 DBWR을 사용해서 storage로 내려 재활용이 되게 해야한다
실운영에서 발생 원인
- 대량 범위의 random io Access를 하는 SQL 이 자주 호출될 경우, buffer cache를 많이 잡고 있기 때문에 다른 작업들이 wait하게 된다
- free buffer를 잡지 못한 server process는 DBWR한테 요청을 하고 대기를 하는게 "free buffer waits".
- 요청 내용은 : to.DBWR "buffer에 있는 Dirty buffer를 storage에 write해서 비워줘"
- 백그라운드 프로세스인 DBWR(db writer)이 OS에 file io를 요청하고 기다리는걸 "db file parallel writ" 라고 한다.(OS에서 ACK 받으면 wait는 풀리게 된다 )
- 만약에 다른 server process 가 DBWR이 write하고 있는 block(buffer cache내의 dirty block중 하나)을 접근하려고 한다면? 그 프로세스는 "write complete waits" 가 발생해서 IO가 끝날 때 까지 기다린다. (??? 의문, SELECT면 그냥 읽어도 될거 같은데...) (잘 발생안함)
발생원인 및 개선방안
1. 대량 범위를 Access 하는 악성 SQL
-> SQL 튜닝 (최소 block만 Access하도록)
(참고. OLTP 서비스에서는 index tuning이 6-70% 된다)
-> Direct I/O로 유도가능한지 검토
- buffer에 올리지 말고 storage에서 바로 접근
- 잘못된 index를 만들어서 Random Access 하게 만들어서 Direct I/O도 못쓰고 , 잘못 만든 index는 index block 전체 scan해야되는거면 Direct IO하는 full scan이 좋을 수도 있다
2. 느린 Storage I/O write 성능
->Storage 변경
- storage IO가 느린걸 수도 있다
- db file parallel write 의 wait 시간이 10~20ms 이상 된다? - 그럼 storage 성능 자체를 점검해야한다 . 좋은 storage로 바꿀 수 있는 기회
-> DBWR 수를 증가시켜 해소할 수도 있다
- 보통 Storage IO가 Async IO를 지원한다. 그럼 DBWR 1개도 충분하다
- cpu core가 여유있다면, CPU_COUNT/8 정도로 DBWR을 생성한다 (16core 시스템이라면 2(16/8)개정도는 DBWR을 위해) - db_writer_process=CPU_COUNT/8
3. DBWR의 많은 작업량
-> 잦은 checkpoint가 발생하는지 확인한다
- 'fast_start_mttr_target' 이라는 recovery 시간을 조정하는 파라미터가 있다
- 값을 줄이면 checkpoint 를 자주해서 instance recovery할 데이터양을 줄일 수 있다
- 해당 파라미터 값이 지나치게 작아서 checkpoint를 자주 발생한다면, 값을 늘리는 방안을 고려해보자
4. write complete waits 와 db file parallel write가 일반적으로 나타난다면?
-> storage io 성능 자체를 의심해봐야한다 ㅎㅎ
'DBMS > Oracle' 카테고리의 다른 글
| [Oracle] Wait Event - Log Buffer Space , Log File Switch Completion, Log File Switch란? (0) | 2024.05.15 |
|---|---|
| [Oracle] Wait Event - Log File Sync, Log File Parallel Write 란? (0) | 2024.05.15 |
| [Oracle] Wait Event - Buffer Cache (0) | 2024.05.15 |
| [Oracle] Wait Event - Latch, Enqueu, Mutex (0) | 2024.05.12 |
| [Oracle] Wait event - Direct Path Read & Direct Path Write (0) | 2024.04.28 |